Escritura en plain text, citas y automatización
Esto estaba en borrador desde hace mucho tiempo, porque usualmente recibo consultas sobre cómo escribir en plain text y cuestiones vinculadas al manejo de la bibliografía (especialmente con referencia a la automatización de citas). Una consulta de Claudio Ruiz—quien me presentó el mundo Markdown y pandoc hace muchos años—me terminó de empujar a publicar y a actualizar, porque la metodología (mí metodología) fue cambiando mucho con el paso del tiempo. Lo que sigue es, entonces, una forma de producir que me resulta útil a mí. No es la mejor, quizás no sea para usted, pero aquí está.
El primer paso es justificar la excentricidad. Lo que empezó como una preferencia por al escritura “libre” (es decir, sin restricciones de licencias y de formatos) terminó siendo una metodología de producción académica. La comparto con la advertencia previa porque creo que tiene los siguientes beneficios:
Permite separar a la escritura del acto de formateo de los documentos. Sirve para enfocar nuestra atención y aprovechar el tiempo al máximo. En general, darle formato a un documento lleva tiempo y, a menos que se tengan muy buenas prácticas, el proceso ante un procesador de texto, tanto en versión propietaria (Word) como libre (p.ej., Libre Office) es un proceso engorroso y muy error-prone.
Permite un manejo automatizado de citas. En la producción académica, las citas son una gran parte del trabajo. Como cualquier investigador sabe, las citas son los que nos permite recorrer una literatura, descubrir su desarrollo, ver su evolución. Sin citas no podría haber producción académica. En general, el trabajo de citar puede ser molesto si no se tiene un flujo de trabajo cuidadosamente diseñado. Las herramientas que voy a compartir son—además de ser software libre as in freedom—útiles para hacer ese trabajo más rápido y de manera más consistente. Adoptar estas herramientas permite escribir sin prestar atención al formato de la cita hasta la etapa final del borrador.
Da mejores resultados estéticos. Los procesadores de texto, basados en el modelo de WYSIWYG son notablemente malos en términos de diseño. Tienen tipografías poco sofisticadas (aunque, algunos clásicos, nunca decepcionan como Times, Times New Roman o Garamond) y—en general—el manejo de los espacios de la página es bastante arbitrario. A menos que se tenga (a) un template muy bien diseñado o (b) un cuidadoso trabajo de armar cada elemento con criterios tipográficamente aceptables, el resultado final es—en general—una catástrofe. Las herramientas que voy a compartir tienen dos ventajas en relación a esa alternativa. En primer lugar, delegan muchas de esas decisiones a un programa que tiene los parámetros aceptables de la tipografía ya incorporados a su código, diseñado por nada más y nada menos que Donald Knuth. Eso significa que es difícil cometer errores tipográficos: el programa permanentemente intenta impedir que hagamos tonterías. En segundo lugar, las herramientas que compartiré facilitan la conversión de formatos: es fácil convertir nuestros textos en archivos
docx,otd,pdf,html,epubetcétera.
Herramientas y flujo de trabajo
Escribir en Markdown
El primer paso es empezar a escribir en Markdown. Es una forma de escribir que es independiente del formato y puede hacerse sobre diversas herramientas: desde un mismo procesador de texto hasta el “Bloc de notas” de un sistema operativo como Windows. Personalmente, prefiero Sublime Text 3, aunque he escuchado buenos reportes de Vim. Si quisiéramos explorar al máximo el mundo del software libre, podríamos probar con Emacs.
Lo bueno de estos programas es que permiten diversas formas de manipulación de texto (como la multiselección) y están disponibles en múltiples plataformas. También permiten un manejo casi automatizado de las versiones de los documentos, algo que se puede hacer—por ejemplo—con Git. En mi caso, como los archivos en Markdown son muy livianos, prefiero hacer esto de manera manual (p.ej., borrador_capitulo_v2.md), aunque a medida que los proyectos se vuelven más complejos y muy dependientes en análisis de datos la opción de un mecanismo automatizado parece más atractiva. Aprender a escribir en Markdown es facilísimo: no lleva más de diez minutos.
Una vez que aprendimos a hacer eso podemos crear nuestro primer archivo en Markdown.
| |
Podemos guardar ese archivo como borrador.md.
Convertir a otros formatos
Para procesar ese texto, vamos a necesitar algunos programas que hay que instalar. Aquí identifico a los que yo uso, en algunos casos hay alternativas (p.ej., Zotero puede ser reemplazado por Mendeley o Papers). Con asterisco, los esenciales.
Una vez que tenemos instalados todos los programas podemos empezar por la conversión más sencilla: de Markdown a PDF. Ello requiere ir al comando de línea y dar la siguiente orden, desde la carpeta en la que se encuentre el archivo que queremos convertir.
| |
La orden es que pandoc convierta el archivo Markdown en un ouput (-o): formato PDF. Para realizar esta conversión, Pandoc utiliza un motor de LaTeX. Veremos más adelante que, en ocasiones, podemos precisarlo (y tiene sus ventajas). El proceso se ve más o menos así:
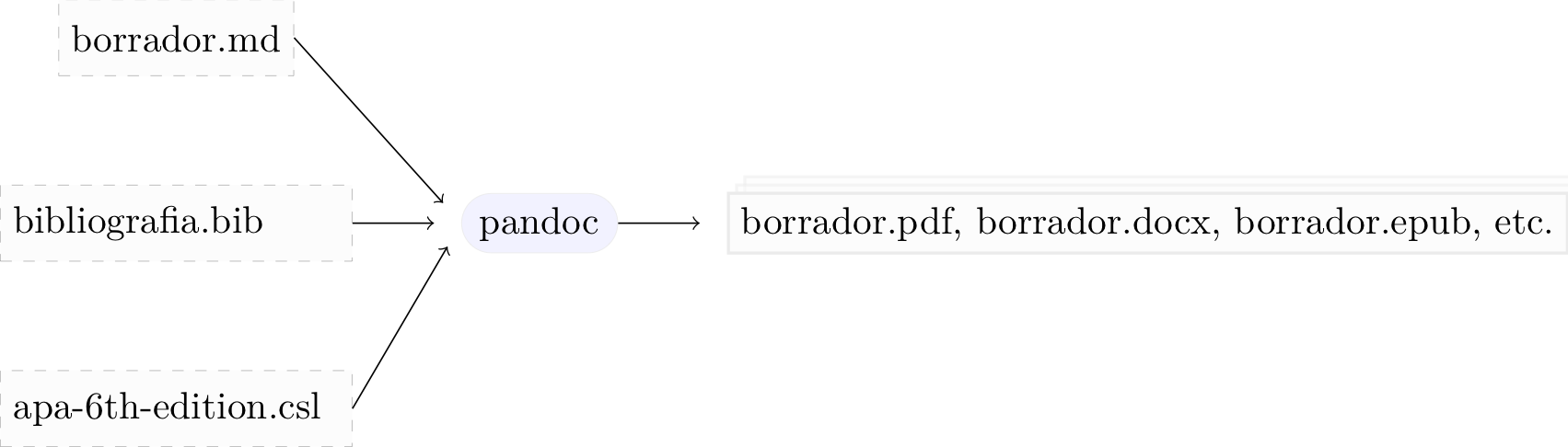
Bibliografía y formatos de citas
La bibliografía debe estar guardada en formato .bib o .json. Eso lo podemos hacer de manera sencilla con diversos organizadores de bibliografías en este formato. Yo utilizo Zotero porque (a) es software libre y (b) funciona como un gran ordenador de materiales, tanto físicos como digitales (los PDF se guardan en el mismo Zotero o en una carpeta de Dropbox o Google Drive vinculada a Zotero). El uso de Zotero no debería presentar mayores dificultades: es como un sistema de archivos dedicados sólo al manejo de bibliografías académicas y de investigación.
Desde Zotero, lo que tenemos que hacer es exportar los trabajos que forman parte de nuestra bibliografía al formato .bib o .json 1. También se puede mantener un archivo .bib actualizado permanentemente de manera automática con AutoZotBib, pero yo hasta el momento preferí que cada proyecto tenga su propio archivo de bibliografía. Así, p.ej, podemos llamar a nuestro archivo con bibliografía bibliografia.bib. La construcción de nuestro archivo de bibliografía la podemos hacer de dos maneras: a través de la selección de los diversos ítems que la integran y su posterior extracción desde Zotero o a través de la conformación manual del archivo, gracias a un shortcut que permite Zotero en Preferences > Export > Quick Copy. La primera opción exige ir guardando cada ítem en una carpeta o con el mismo tag (la segunda opción parece más versátil, porque—por ejemplo—yo tengo a Zotero organizado por carpetas temáticas más que de proyecto). La segunda opción es la que uso usualmente: a medida que voy escribiendo, voy agregando manualmente gracias al Quick Copy de Zotero cada ítem a un archivo .bib o .json que mantengo actualizado. En general hacia el final pandoc me informa que hay varias citas que no están en la bibliografía, así: reference post2010 not found. Cuando eso me pasa junto todos los ítems faltantes, los pego en Sublime Text y ahí corro los comandos unique lines y sort lines para eliminar duplicados y ponerlos en orden alfabético. Completar la bibliografía no me lleva más de quince minutos, incluso cuando los faltantes son cerca de cien.
Ese archivo de bibliografía va a ser así:
| |
O así optamos por bibliografia.json:
| |
Fíjense que ambos archivos tienen todos los datos necesarios para construir una bibliografía: título, autor, publicación, volumen, etcétera. Esta información en Zotero se puede cargar de tres maneras distintas:
La podemos cargar manualmente en Zotero, cuando queremos p.ej., cargar los datos de un libro viejo que tenemos en casa, un fallo judicial que no está en repositorios en línea, etcétera.
Si el libro es nuevo, lo podemos buscar en Google Books o Amazon. Si lo encontramos, con el Zotero Connector carga la información directamente desde la página.
La mayoría de los repositorios de papers académicos (incluido Google Scholar) permite—también—usar el botón de conector de Zotero.
En general la información se carga bien, pero a veces tenemos que revisar que la carga haya sido bien hecha (p.ej., quizás el conector no puso la información sobre el “volúmen” de la Revista Académica correspondiente). En esto, el mejor flujo de trabajo es uno que se preocupa de que la información se cargue bien “la primera vez” (y luego nos podemos olvidar de eso).
Ahora podemos hacer que nuestra cita al texto de Post tenga una forma determinada de acuerdo a un estilo de cita determinado. Para buscar esos estilos, debemos ir al Zotero Style Repository y elegir. Probemos p.ej. con APA, sexta edición. Vamos a obtener un archivo apa-6th.edition.csl y lo vamos a colocar an la carpeta en la que está nuestro borrador.md y nuestra bibliografia.bib. Tenemos ahora todo para producir nuestro documento, con la cita que deseamos, y en el formato que deseamos. Empecemos por una conversión a formato PDF.
| |
Lo que agregamos es lo siguiente:
- Con
--citeprocle damos la orden apandocpara que considere la bibliografía. - Con
--bibliographyidentificamos el archivo correspondiente. - Con
--cslidentificamos el estilo que queremos usar. - Con
--pdf-engineidentificamos el motor de LaTeX que se va a usar para hacer la conversión (sirve si usamos fuentes tipográficas fuera de las que vienen por default; en ese caso usoxelatex).
Para convertir a otros formatos la cosa es aún más sencilla:
| |
Fintas adicionales
Es posible que el formato de PDF por default de Pandoc (que es el de LaTeX) no nos guste y queramos uno propio. En realidad nos debería gustar — hay muchos campos en dónde el PDF por default que produce LaTeX es el estándar para borradores de todo tipo. Pero si queremos algo más personalizado, hay muchos templates ahí afuera. Yo personalmente tengo varios: uno para las notas de clases (para producir outlines), uno para el CV inspirado en el vita de Kieran Healy, uno para reportes breves, uno para cartas (!), uno para papers individuales en versión borrador, uno para formato “capítulo de tesis”, etcétera. Entrar en este mundo es complejizar más el proceso: requiere familiarizarse con la forma en que los archivos .latex (los templates que se pueden usar) están programados. Requiere empezar a “meter mano” a temas como espaciado, interlineado, tamaño de fuente, estructura de títulos (numeración, sangría), etcétera. Es un camino de ida, que permitirá—por ejemplo—usar tipografías poco utilizadas, o no fácilmente disponibles. No lo recomiendo porque (a) es una forma de perder tiempo, lo que va en contra de la idea de enfocarnos solamente en la lectura; (b) tiene una curva de aprendizaje pronunciada y (c) es la forma más fácil de cometer gruesos errores tipográficos.
Por eso, y para borradores, trabajos prácticos, tesis de licenciatura, maestría e incluso doctorales, el formato por default de LaTeX debería ser suficiente. Como decía, en muchos campos de investigación (especialmente, las ciencias duras) este es el formato de preferencia. Así que escribir un borrador en LaTeX tiene ese no se qué adicional de “parecer profesional” (incluso sin tener—todavía—el título habilitante). Usar el default es estar in y eso (en este club) es bueno.
Quizás tiene más sentido modificar el formato del template de Word: el que usa Pandoc por default me parece muy malo. Eso es sencillo: hay que crear un documento con las características que queramos que tenga (interlineado, tipo de letra, títulos bien codificados, etcétera) y guardarlo (vacío o con texto, no importa) como reference.docx en la carpeta que tenemos de borrador. Luego podemos convertir de Markdown a DOCX (que muchos piden a la hora de p.ej., enviar un archivo) con el siguiente comando:
| |
Algo que sí parece importante es familiarizarse con los campos de YAML que permite Pandoc. Así es posible ponerle a nuestros borradores título, afiliación, institución, abstract, etcétera. Comparto abajo, p.ej., dos opciones, una sencilla y otra más compleja. La sencilla es nuestro archivo borrador.md con un preámbulo YAML sencillo, al que le podemos poner borrador_con_titulo.md.
| |
La opción compleja es el YAML del último paper que escribí.
| |
La complejidad mayor se debe a que empecé a usar rmarkdown como forma de disparar pandoc. Permite un nivel de precisión mayor de algunas cosas, como—por ejemplo—el manejo de las figuras por default, algo útil en proyectos que usan muchos datos. Además, permite escribir el código para manejar esos datos dentro del mismo archivo, en un formato .rmd. Por otro lado, el YAML más complejo identifica templates y preámbulos de LaTeX personalizados. Esta alternativa es mejor que controlar Pandoc desde la línea de comandos porque las ordenes se vuelven demasiado largas. Pero esto ya es un uso avanzado de las herramientas, aquí sólo quería compartir lo básico.
Los archivos de los ejemplos dados acá están en un repositorio.